
OpenAI’s GPT-3 has been grabbing headlines almost as fast as the neural-network language model can generate them. Since its private beta release in July 2020, natural language processing (NLP) experts have been blown away by the sheer scale and complexity of the project.
Yet flying under the radar is another approach to NLP that could overcome a significant bottleneck faced by GPT-3 and other large scale generalized NLP projects. Google’s PEGASUS model not only shows remarkable promise when it comes to text summarization and synthesis, but its non-generalized approach could push industries such as healthcare to embrace NLP much earlier than was once supposed.
Generalized v. Specific Pre-Training Objectives
GPT-3’s transformer encoder-decoder model is essentially an autocomplete tool with billions of weighted connections, or parameters, between words that can predict the likelihood of one word following another. The power in OpenAI’s latest solution is in its astounding size. The first GPT had only 117 million parameters. GPT-2 had 1.5 billion parameters. GPT-3 has 175 billion parameters.
This is an order of magnitude larger than its next closest competitor, and it’s allowed GPT-3 to stay highly generalized while still being easily applied to specific tasks. This means that pre-training, or the early modeling of the neural network against vast datasets, is done without a specific goal in mind, but, once generally trained, it can learn a new task while only being fed a handful of examples rather than the tens of thousands that other models require. Want it to translate a book into Korean? Feed GPT-3 a few words of English and the corresponding Korean words, and it will do the rest.
Yet bigger might not always be better, and the OpenAI team cedes that its model might be running into the limits of generalized pre-training in a 75-page paper called Language Models are Few-Shot Learners. “Our current objective weights every token equally and lacks a notion of what is most important to predict and what is less important,” they explain, highlighting the importance of having specific pre-training objectives.
Abstract Text Summarization and Synthesis
This means that a massive yet generalized approach in pre-training, while impressive and remarkably flexible, might not be the answer for many tasks. In fact, the OpenAI team mention in the paper’s limitations section that GPT-3 still has “notable weaknesses in text synthesis.”
A team at Google has created the PEGASUS model to fix weaknesses in text synthesis and abstractive text summarization – one of the most challenging tasks in NLP because, unlike traditional text summarization, it doesn’t merely highlight key passages, but generates entirely new text. As they explain in their blog, “our hypothesis is that the closer the pre-training self-supervised objective is to the final down-stream task, the better the fine-tuning performance.”
PEGASUS was able to align their pre-training self-supervised objectives with the down-stream task of text summarization through gap-sentence generation (GSG). The idea with GSG is that certain sentences are removed from a document and the model must then predict those sentences.

By pre-training with GSG and then fine-tuning their model on text summarization datasets, PEGASUS was able to achieve state-of-the-art results. Impressively, it reached near human-like accuracy in under 1,000 fine-tuned examples.
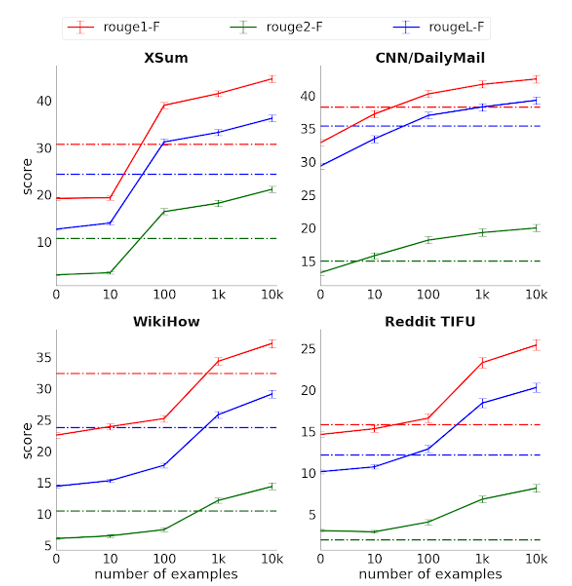
During pre-training, three variants of the ROGUE score were used (higher the better). In some cases, PEGASUS outperformed the baseline in under 100 examples, approaching the efficiency of GPT-3 with .3% of its parameters.
Although the ROGUE score is useful, ultimately you must test the validity of the summary using human experts. The Google team had people evaluate PEGASUS text summaries against human-written summaries without knowing which was which. The results were indistinguishable. PEGASUS was even able to pull out ideas that had only been implied in the original text such as the specific number of ships in a particular passage, although it didn’t always do this perfectly. This highlights that pre-training with specific objectives might be the future of abstractive text summarization.
Healthcare and BFSI Applications
With this new model for text summarization and others that embrace a non-generalized pre-training objective framework, there are several key healthcare and banking, financial services and insurance (BFSI) use cases that are growing in importance:
- Streamlining Research: Healthcare and financial data is growing exponentially, and researchers and clinicians alike are already struggling to process and understand the vast sums of information that are being produced daily. Text summarization could drastically reduce the amount of time they spend pouring through individual papers, reports, data, etc. to find key highlights while also identifying possible trends across multiple documents.
- Q&A Chatbots: One of the most important areas for efficiency and positive patient/customer experience is ensuring that they can have their questions answered quickly. Text summarization tools could help customers resolve their most pressing banking issues and patients triage their symptoms to find the help that they need as quickly as possible while reducing the burden on financial and healthcare professionals.
- Scripting and Summarizing Telemeetings: As telehealth balloons during the pandemic, more patient data than ever is digital. Similarly, more customers are making use of remote meeting technology to interact with their financial institutions. Text summarization could help healthcare and financial organizations turn speech into text, take notes, and then summarize that information in an easily digestible fashion.
- Supporting Decisions: Text summarization could also compile the information from these scripted notes with other electronic health records or financial data that is often unstructured and narrative in form. This could help physicians make decisions about drug dosing, remind them about patient-specific allergies, and detect and alert physicians about presentations of specific diseases, while also helping financial professionals approve loans, evaluate stocks, and quickly derive market signals.
- Creating Legal, Insurance, and Billing Efficiencies: Healthcare and BFSI come with significant legal requirements, and text summarization could help streamline this process so that people can easily understand long legal documents through legal contract analysis that highlights and summarizes the riskier sections. Additionally, the healthcare system is full of complicated medical codes for insurance and billing, and text summarization could quickly review and summarize physicians’ notes to pull out the proper designations.
Have a Goal in Mind
Regardless of the hype or potential limitations of GPT-3, it is an amazing tool that will only grow more sophisticated over time. We’re living in the golden age of NLP and text summarization that is opening up efficiencies in healthcare and BFSI that couldn’t have been imagined even 5 years ago. Healthcare and financial organizations should explore how they can apply text summarization, keeping in mind the potential power of models that are pre-training with clear objectives aimed at downstream applications.
About the Author

Dattaraj Rao, Innovation and R&D Architect at Persistent Systems, is the author of the book “Keras to Kubernetes: The Journey of a Machine Learning Model to Production.” At Persistent Systems, Dattaraj leads the AI Research Lab that explores state-of-the-art algorithms in Computer Vision, Natural Language Understanding, Probabilistic programming, Reinforcement Learning, Explainable AI, etc. and demonstrates applicability in Healthcare, Banking and Industrial domains. Dattaraj has 11 patents in Machine Learning and Computer Vision.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind